
🐍 Newsletters
AI Snake Oil
39 min read
Open-world evaluations for measuring frontier AI capabilities
Introducing CRUX, a new project for evaluating AI on long, messy tasks
Your hub for Ai Evaluation news and research — curated daily from 50 top AI sources including OpenAI, Anthropic, Google DeepMind, and more. Every article is reviewed and enriched with editorial analysis by the DeepTrendLab team.
Introducing CRUX, a new project for evaluating AI on long, messy tasks

Note: you are ineligible to complete this challenge if you’ve studied Ancient or Modern Greek, or if you natively speak Modern Greek, or if for other reasons you know what…

LLM-based chatbots’ capabilities have been advancing every month. These improvements are mostly measured by benchmarks like MMLU, HumanEval, and MATH (e.g. sonnet 3.5, gpt-4o). However, as these measures get more…
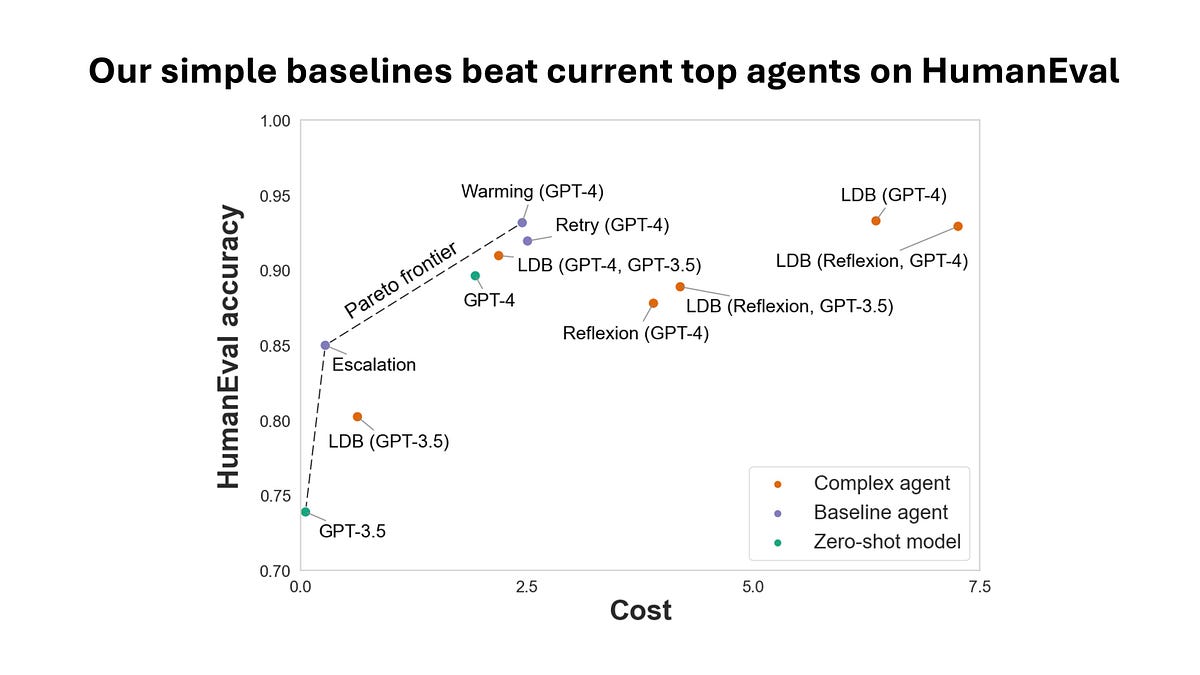
What spending $2,000 can tell us about evaluating AI agents